FDA: An attack to corrupt the core of AI models!
Despite the success of Deep Learning in enhancing the state-of-the-art in various computer-vision and NLP tasks, they remain highly susceptible to adversarial attacks. What is an adversarial attack? An adversarial attack is a manipulation of the input to any model, such that, while the manipulated input remains indistinguishable from the original input to human observers, it changes the prediction of the model. In the case of image classification using deep learning, a typical examples is as follows:

An imperceptible noise is added to the image of a “Hummingbird” such that, while the noise is imperceptible to the human eyes, the output of the Deep Network is changed. In this case, the network now believes that the image contains a “Gibbon”. Such a noise is known as a adversarial perturbation, and the resulting image is know as the adversarial image.
Now, Deep networks act as not only classifiers, but also as Deep-Feature extractors for driving various computer vision applications such as image retrieval (retrieval of relevant images), image captioning (machine description of given image), and artistic style transfer. An interesting and important question to ask at this point is: Are the Deep-features extracted from adversarial images also corrupt? That is, in addition to changing the image label, will they also critically damage the outcome of downstream tasks such as captioning and style-transfer?
In a recent work from Video Analytics lab (http://val.cds.iisc.ac.in), IISc (FDA: Feature Disruptive Attack), the authors (Aditya Ganeshan, B.S. Vivek, and Prof. Venkatesh Babu) found that the Deep-Features of adversarial images generated from existing attacks indeed contain information that can be used for downstream tasks indicating the weakness of existing attacks. This weakness shows that without the knowledge of the downstream task, the attacker may not be able to affect the outcome of the various tasks performed on the adversarial image he/she generated.
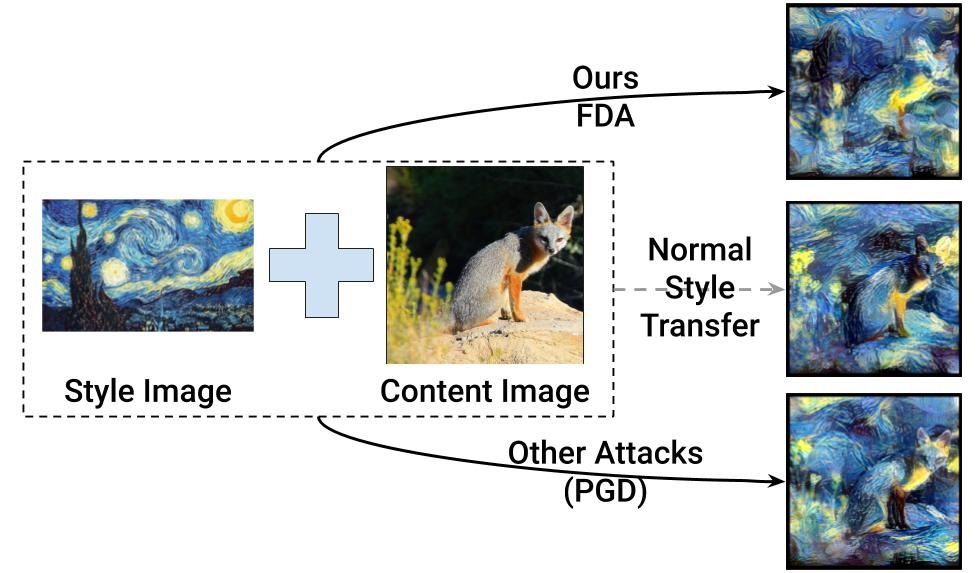
FDA is the first attack to show task-agnosticity. That is, FDA enables attack on style-transfer and captioning without any knowledge of those tasks. This development hints at existence of Task-agnostic perturbations which may be able to damage a wide variety of task without any knowledge of those tasks. In future, Prof. Venkatesh Babu and his team hope to explore this direction.
Interested Readers can:
1) Read the paper here: https://arxiv.org/abs/1909.04385,
2) Try the code here: https://github.com/BardOfCodes/fda,
3) Follow a code walk-through on Google Collab here: https://colab.research.google.com/drive/1WhkKCrzFq5b7SNrbLUfdLVo5-WK5mLJh.
Reference:
Aditya G., Vivek B.S., and R. Venkatesh Babu, “FDA: Feature Disruptive Adversarial Attack”, in International Conference on Computer Vision (ICCV), 2019. [arXiv]


