Self-supervised methods to perceive humans in the 3D world
When we look at a picture of someone, our brain can easily decode the 3D model of the person and their surrounding without ambiguity. This is one of the most difficult tasks for a machine attempting to analyse an image since the third dimension (depth) is lost when we take a picture using a camera. Developing a machine with such capability is of great interest for a variety of applications such as human-computer interaction, assistance in physical therapy (detecting abnormalities in a patient’s posture), automatic tutoring systems for athletes, video surveillance, etc.
Most of the recent supervised approaches heavily rely on the availability of large-scale datasets with paired 3D pose annotation. However, there are many drawbacks. Unlike 2D landmarks, it is difficult to manually annotate 3D human pose on 2D images. A usual way of obtaining 3D ground-truth annotation is through an in-studio multi-camera setup which is difficult to configure outdoors. This results in a limited diversity in the available 3D pose datasets. Thus, a model trained on such datasets often performs unsatisfactorily on samples from unseen wild environments.
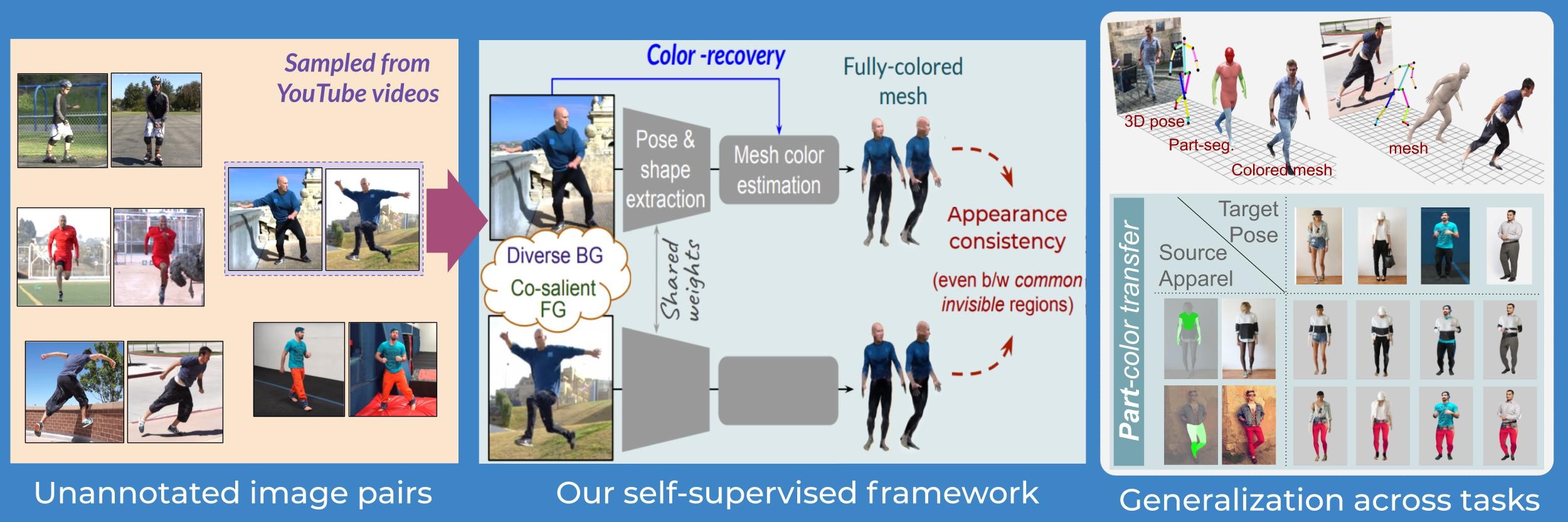
To address this, researchers in the Video Analytics Lab (http://val.cds.iisc.ac.in) at the Department of Computational and Data Sciences aim to investigate self-supervised learning frameworks that do not rely on any paired annotation. The motivation is quite straightforward. Producing a dataset with clean labels is expensive but unlabeled data is being generated all the time. To make use of this large amount of unlabeled data, one way is to set the learning objectives properly so as to get supervision from the data itself. In their framework, they relied on image-pairs depicting the same person in varied poses and backgrounds (BG). Such image pairs are obtained from single-person action videos, which are available abundantly on the internet (first panel of the figure). Following this, the training is driven by a foreground (FG) appearance consistency objective (second panel of the figure). In the absence of paired supervision, this appearance consistency not only helps us to segregate the common FG human from their respective wild BGs but also discovers the required pose deformation in a fully self-supervised manner. Additionally, to avoid degeneracy, the researchers constrain the intermediate pose representation by formalising different ways to inculcate prior knowledge of human pose articulation.
In the first paper, the team leveraged prior knowledge in the form of a part-based 2D puppet model, and by accessing a set of unpaired 3D poses. In follow-up work, this prior knowledge was instilled by integrating a parametric human 3D mesh model into their self-supervised framework. This opens up the usage of this framework for a variety of appearance-related tasks beyond the primary task of 3D pose and shape estimation. One such task is “part-conditioned appearance transfer” as shown in the last panel of the figure. This approach can be seen as a first step towards realising next generation deployment friendly, and self-adaptive human mesh recovery systems.
REFERENCE:
- Jogendra Nath Kundu, Siddharth Seth, Varun Jampani, Mugalodi Rakesh, R. Venkatesh Babu, and Anirban Chakraborty. “Self-Supervised 3D Human Pose Estimation Via Part Guided Novel Image Synthesis”, accepted in IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2020) [Oral – top 5.7% of submissions].
- Jogendra Nath Kundu, Mugalodi Rakesh, Varun Jampani, Rahul M V, and R. Venkatesh Babu. “Appearance Consensus Driven Self-Supervised Human Mesh Recovery”, accepted in the European Conference on Computer Vision (ECCV 2020) [Oral – top 2% of submissions].
PROJECT PAGES:
http://val.cds.iisc.ac.in/pgp-human/
http://val.cds.iisc.ac.in/ss-human-mesh/

VAL team (Venkatesh Babu, Jogendra and Siddharth)