20 November 2024
– Parth Kumar
A large number of 2D materials like graphene can have nanopores – small holes formed by missing atoms through which foreign substances can pass. The properties of these nanopores dictate many of the materials’ properties, enabling the latter to sense gases, filter out seawater, and even help in DNA sequencing.
“The problem is that these 2D materials have a wide distribution of nanopores, both in terms of shape and size,” says Ananth Govind Rajan, Assistant Professor at the Department of Chemical Engineering, Indian Institute of Science (IISc). “You don’t know what is going to form in the material, so it is very difficult to understand what the property of the resulting membrane will be.”
Machine learning models can be a powerful tool to analyse the structure of nanopores in order to uncover tantalising new properties. But these models struggle to describe what a nanopore looks like.
Govind Rajan’s lab has now devised a new language which encodes the shape and structure of nanopores in the form of a sequence of characters, in a study published in Journal of the American Chemical Society. This language can be used to train any machine learning model to predict the properties of nanopores in a wide variety of materials.

A selection of nanopores that could be present in graphene along with their STRONG-based names. The white arrow indicates the starting atom and each STRONG is written by traversing the nanopore rim atoms in an anti-clockwise direction (Image: Piyush Sharma)
Called STRONG – STring Representation Of Nanopore Geometry – the language assigns different letters to different atom configurations and creates a sequence of all the atoms on the edge of a nanopore to specify its shape. For instance, a fully bonded atom (having three bonds) is represented as ‘F’ and a corner atom (bonded to two atoms) is represented as ‘C’ and so on. Different nanopores have different kinds of atoms at their edge, which dictates their properties. STRONGs allowed the team to devise fast ways for identifying functionally equivalent nanopores having identical edge atoms, such as those related by rotation or reflection. This drastically cuts down on the amount of data that needs to be analysed for predicting nanopore properties.
Just like how ChatGPT predicts textual data, neural networks (machine learning models) can “read” the letters in STRONGs to understand what a nanopore will look like and predict what its properties will be. The team turned to a variant of a neural network used in Natural Language Processing that works well with long sequences and can selectively remember or forget information over time. Unlike traditional programming in which the computer is given explicit instructions, neural networks can be trained to figure out how to solve a problem they have not encountered so far.
The team took a number of nanopore structures with known properties (like energy of formation or barrier to gas transport) and used them to train the neural network. The neural network uses this training data to figure out an approximate mathematical function, which can then be used to estimate a nanopore’s properties when given its structure in the form of STRONG letters.
This also opens up exciting possibilities for reverse engineering – creating a nanopore structure with specific properties that one is looking for, something that is particularly useful in gas separation. “Using STRONGs and neural networks, we screened for nanoporous materials to separate CO2 from flue gas, a mixture of gases released on fuel combustion,” says Piyush Sharma, former MTech student and first author of the study. This process is critical for reducing carbon emissions. The researchers were able to identify a few candidate structures that could effectively capture CO2 from a mixture that includes oxygen and nitrogen.
The team is also looking into the idea of creating digital twins of 2D materials. “Let’s say you collect a lot of experimental data on a material. You can then try to see what would have been the collection of nanopores which would have led to this performance,” says Govind Rajan. “With this digital twin of the material, you can do a lot of things – predict the performance for the separation of a different set of gases, or you can come up with entirely new use cases for the same material.”
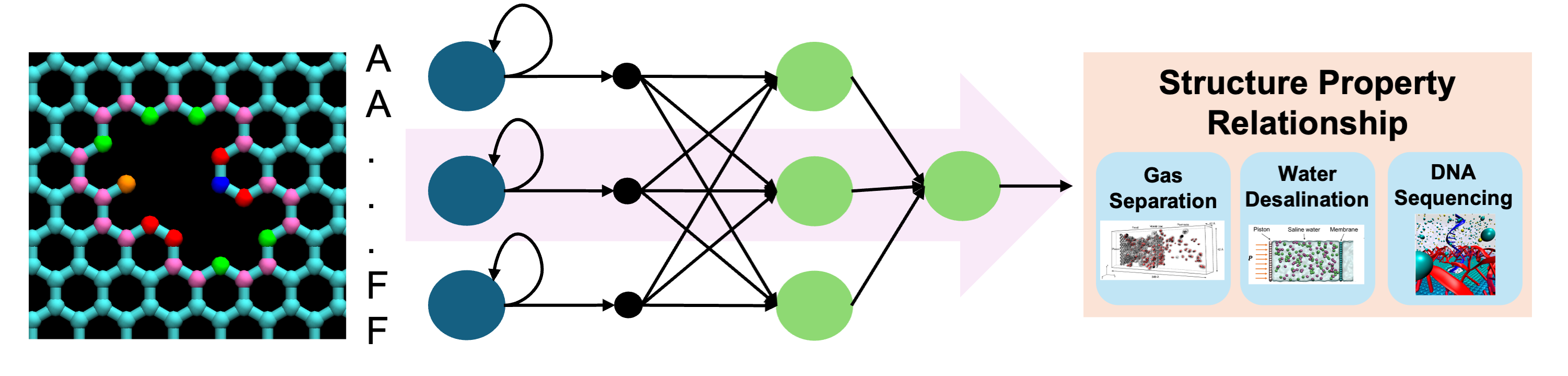
A schematic depicting how the STRONG of a nanopore is processed through a neural network, finally leading to the prediction of the property associated with that nanopore. The resulting structure-property relationships find use in various application areas, such as gas separation, water desalination, and DNA sequencing. Application images are adapted from open-access articles (Appl. Sci. 2018, 8(9), 1547, npj 2D Mater. Appl. 2021, 5, 66, and ACS Appl. Mater. Interfaces 2017, 9(1), 92). (Image: Piyush Sharma)
REFERENCE:
Sharma P, Thomas S, Nair M, Govind Rajan A, Machine Learnable Language for the Chemical Space of Nanopores Enables Structure–Property Relationships in Nanoporous 2D Materials, Journal of the American Chemical Society (2024).
https://pubs.acs.org/doi/10.1021/jacs.4c08282
CONTACT:
Ananth Govind Rajan
Assistant Professor
Department of Chemical Engineering
Indian Institute of Science (IISc)
Email: ananthgr@iisc.ac.in
Phone: +91 80 2293 3702
Website: https://agrgroup.org/
NOTE TO JOURNALISTS:
a) If any of the text in this release is reproduced verbatim, please credit the IISc press release.
b) For any queries about IISc press releases, please write to news@iisc.ac.in or pro@iisc.ac.in.
